Monitorer son SI avec Centron EMS de manière disruptive
Si monitorer son SI avec une application de monitoring semble facile, le faire sur une vision métier et une approche business est tout autre. Aperçu de la méthode en cours d’implémentation.
Paradigme de départ
Déployer des sondes de monitoring sur un ensemble de systèmes pour en sortir un état brut à un instant t est une méthode empirique qui fonctionne. Mais cette vue instantanée sera forcément faussée assez rapidement quand le nombre de sondes va augmenter.
Maintenir une matrice d’alerte est quelque chose de compliqué et qui demande un investissement certain. Mais n’allez pas croire qu’elle est inutile pour autant. Ces briques, nécessaires, ne sont qu’un morceau d’une vue que le business vous demandera vous IT de construire. Et le business veut avoir une vue simple et claire (feu tricolore) de l’état de son SI, pas une matrice combinant 2765 sondes pour donner un état.

Ok, mais comment faire ?
Il y a deux axes forts à développer :
- Evidement, les sondes à déployer sur les équipements à monitorer. Elles permettront d’aller en profondeur dans les diagnostics.
- La vue traversante : c’est la vue qui restituera de manière instantanée l’état d’une application ou d’un site web en utilisant ladite application.
Cette vue traversante peut se faire de plusieurs manières :
- script de tests de l’application : je me connecte, j’ouvre une fiche client, je modifie une donnée en base, je sors.
- parcours d’un site web pour tester différentes pages
Lorsque je traverse mon application, je pars du niveau 7 du modèle OSI (couche application) et je descend dans les couches (application support : couche 6, SOA : couche 4 et 5, réseau : couche 2 et 3 et de fait la couche physique (1)) car j’accède à des ressources sur d’autres serveurs via du SOA (micro-services docker dans notre cas).
Que mesurer ?
Il faut, dans le cas des scripts traversants, mesurer un temps type du script et s’en servir de référence. Il faut définir ensuite les différents seuils qui serviront à définir le feu tricolore :
- Tbase + x% = seuil acceptable : feu vert
- Tbase + y% = seuil dégradé : feu orange
- Tbase + z% = seuil critique : feu rouge
Une fois définies x,y,z, on est capable de répondre l’état de notre application.
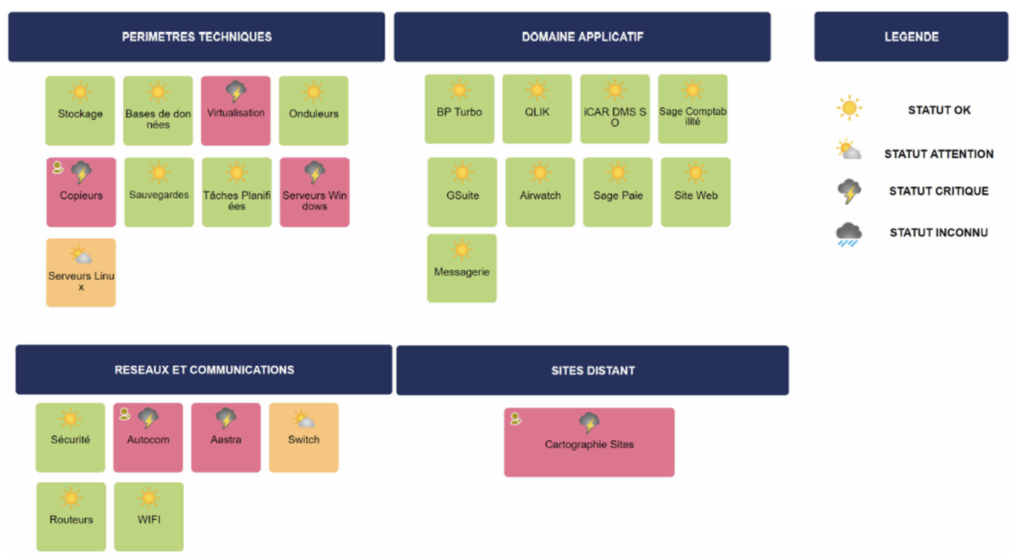
Comment dérouler le projet ?
Il faut dérouler les 2 axes en parallèle :
- Je fais travailler les services études sur la réalisation des scripts (pertinents si possible) et le métier pour définir les seuils x,y,z. Cela permet de donner des résultats rapides et concrets.
- Je déploie l’intégralité des sondes nécessaires au monitoring de mon infrastructure : il faut bien que j’aille voir ce qui cloche quand une application sera rouge !
- En plus de mon feu tricolore sur mon application, je créé une vue dans mon application de monitoring qui agrège tous les services desquels elle dépend : hyperviseur, switch, SOA, … Cette vue sera faite en niveaux, permettant de zoomer sur chaque service unitairement. Par exemple, pour un service réseau :
- Niveau 1 : vue globale réseau
- Niveau 2 : vue des coeurs de réseau et routeurs principaux
- Niveau 3 : vue des switchs de distribution
Que faire en cas de problèmes ?
Si une application est rouge, j’accède à la vue agrégée de mon application et je clique sur la zone en rouge. Je descend ensuite niveau par niveau pour trouver où se situe mon problème. Je peux donc intervenir rapidement et suis beaucoup plus pertinent pour répondre aux utilisateurs de l’application.

Monitorer son LAN avec Php Server Monitor

Exploiter sa sauvegarde hypervault backup

Projet Phase 1 – enceinte pour l’atelier
A propos de l'auteur
Fabien
Professionnel de l'IT dans les infrastructures depuis 15 ans, je pratique aussi à la maison dans les domaines du réseau, de la domotique et de la gestion des données. Je souhaite partager ici tous les projets et toutes les astuces que j'ai mis en place et continue de développer.